前回は、UnityでJoy-Çonを使うため、JoyconLibというライブラリを紹介しました。
nn-hokuson.hatenablog.com
このJoyconLibは、非常に使い勝手がよく、重宝しているのですが、、、、2023年3月現在、Unity2022にインポートするとDllNotFoundExceptionが発生します。これは、JoyconLibで使われているPluginがIntel Mac用にコンパイルされてるためです。
したがって、Apple Siliconの環境でJoy-Conを使う場合は、JoyconLibのPluginをリビルドする必要があります。ここではその方法を紹介します。
hidapiのプロジェクト作成
JoyconLibのPluginをリビルドするため、Xcodeのプロジェクトを作成します。Xcodeを起動し、メニューバーから「macOS」を選択、Framework & Libraryの項目から「Bundle」を選択してください。

「Product Name」は「hidapi」に設定してください。

ソースコードのビルド
必要なソースコードをプロジェクトにインポートします。下記のサイトから次の3つをダウンロードしてください。
- mac/hid.c
- mac/hidapi_darwin
- hidapi/hidapi.h
github.com
ダウンロードしたプログラムを、Xcodeの左カラムにドラッグ&ドロップして、プロジェクトにインポートします。

次に、必要となるフレームワークを追加します。左カラムでhidapiを選択した状態で、中央のメニューからBuild Phasesを選択します。Link Binary With Librariesの項目の「+」をクリックして、「AppKit.framework」を追加してください。

メニューバーから、Product→Buildを選択してビルドします。左カラムのProductsの中にhidapiのbundleが生成されます。
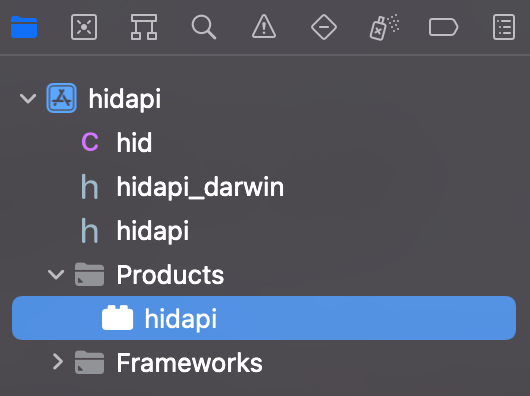
生成されたhidapiのバンドルを選択し、右クリックすると「Show in Finder」というメニューが表示されます。それを選択してFinderにhidapi.bundleを表示しておきましょう。
Unityにhidapiのバンドルを追加する
UnityプロジェクトにJoyconLibをインポートする方法は、前回の記事を参照ください。
nn-hokuson.hatenablog.com
JoyconLibがインポートできたら、Assets/JoyconLib_plugins/macフォルダを開いてください。hidapi.bundleが表示されているので、それを削除し、新しく作成したhidapi.bundleをドラッグ&ドロップでインポートしてください。

最後にUnityを再起動します。再起動しないとbundleがリロードされないので、この手順は必須です!罠です!ご注意ください。
再起動すれば、無事にM1/M2などのApple Silicon製のmacOSでもJoyconLibが使えるようになります。